

4m Token? Minimax-text-01 übertrifft Deepseek v3

chinesische KI macht erhebliche Fortschritte und forderte führende Modelle wie GPT-4, Claude und Grok mit kostengünstigen Open-Source-Alternativen wie Deepseek-V3 und Qwen 2.5. Diese Modelle zeichnen sich aufgrund ihrer Effizienz, Zugänglichkeit und starker Leistung aus. Viele arbeiten unter zulässigen kommerziellen Lizenzen und erweitern ihre Berufung auf Entwickler und Unternehmen.
Minimax-Text-01, die neueste Ergänzung dieser Gruppe, setzt einen neuen Standard mit seiner beispiellosen 4-Millionen-Token-Kontextlänge und übertrifft die typische 128K-256-K-Token-Grenze. Diese erweiterte Kontextfähigkeit in Kombination mit einer hybriden Aufmerksamkeitsarchitektur für Effizienz und einer Open-Source-Lizenz fördert Innovation ohne hohe Kosten.
Lassen Sie uns in die Funktionen von Minimax-Text-01 eintauchen:
Inhaltsverzeichnis
- Hybridarchitektur
- Mischungsmischung (MOE) Strategie
- Trainings- und Skalierungsstrategien
- Optimierung nach dem Training
- Key Innovations
- Kern akademische Benchmarks
- Allgemeine Aufgaben Benchmarks
- Begründung Aufgaben Benchmarks
- Mathematik- und Codierungsaufgaben Benchmarks
- Erste Schritte mit Minimax-text-01
- Wichtige Links
- Schlussfolgerung
Hybridarchitektur
minimax-text-01 gleicht Effizienz und Leistung geschickt aus, indem sie die Aufmerksamkeit der Blitze, die Aufmerksamkeit von Softmax und die Expertenmischung (MOE) integrieren.
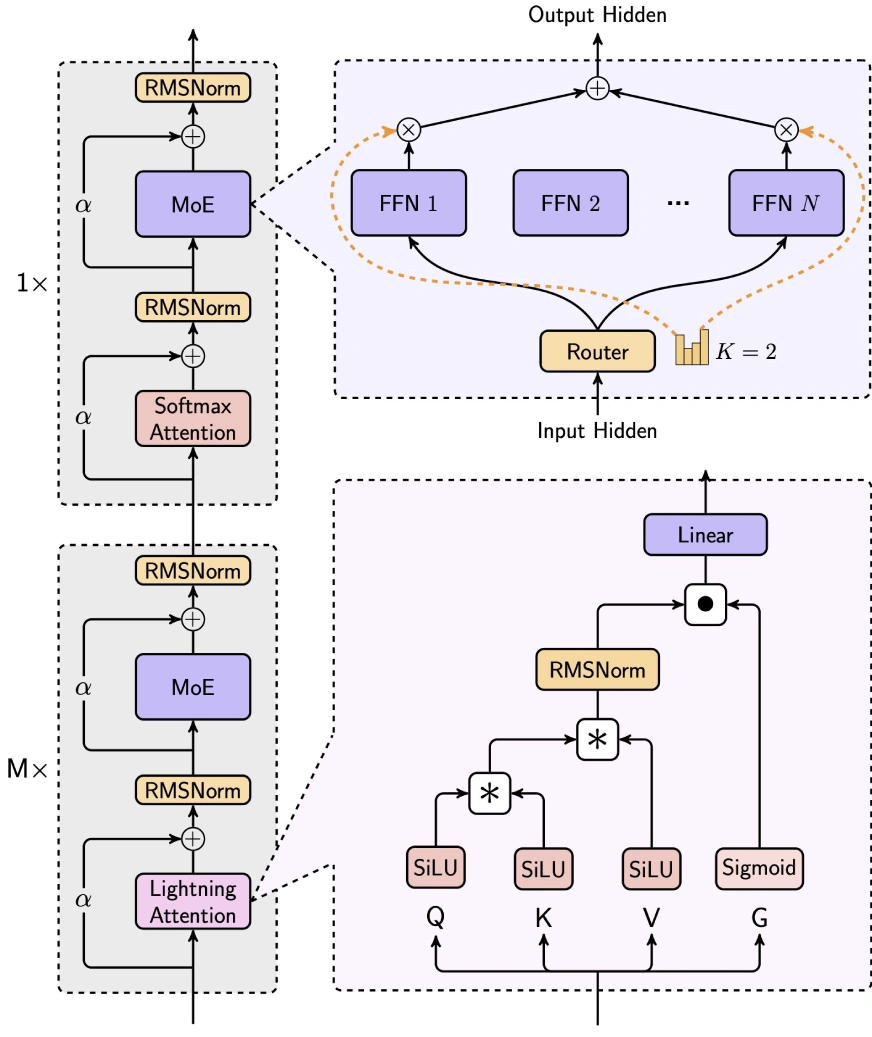
- 7/8 Lineare Aufmerksamkeit (Blitzaufmerksamkeit-2): Dieser lineare Aufmerksamkeitsmechanismus reduziert drastisch die Rechenkomplexität von O (n²d) auf O (d²n), ideal für die langkontexte Verarbeitung. Es verwendet die SILU -Aktivierung für die Eingangstransformation, Matrixoperationen zur Berechnung der Aufmerksamkeitsbewertung sowie RMSNorm und Sigmoid zur Normalisierung und Skalierung.
- 1/8 Softmax Aufmerksamkeit: Ein traditioneller Aufmerksamkeitsmechanismus, der Seil (Rotationsposition einbettet) in die halbe Aufmerksamkeitskopfdimension, die Länge extrapoliert, ohne die Leistung zu beeinträchtigen.
Mischungsmischung (MOE) Strategie
Die einzigartige Moe-Architektur von minimax-text-01 unterscheidet sie von Modellen wie Deepseek-V3:
- Token -Drop -Strategie: verwendet einen Hilfsverlust, um die ausgewogene Token -Verteilung über Experten hinweg aufrechtzuerhalten, im Gegensatz zu Deepseeks Tropfenansatz.
- Globaler Router: optimiert Token -Allokation für die Verteilung der Arbeitsbelastung zwischen Expertengruppen.
- Top-K-Routing: Wählt die Top-2-Experten pro Token aus (im Vergleich zu Deepseeks Top-8 1-Shared Expert).
- Expertenkonfiguration: verwendet 32 Experten (gegen Deepseeks 256 1 geteilt) mit einer versteckten Expertendimension von 9216 (gegen Deepseeks 2048). Die gesamten aktivierten Parameter pro Schicht bleiben die gleichen wie Deepseek (18.432).
Trainings- und Skalierungsstrategien
- Schulungsinfrastruktur: nutzte ungefähr 2000 H100 -GPUs unter Verwendung fortgeschrittener Parallelismus -Techniken wie Experten -Tensor -Parallelität (ETP) und linearer Aufmerksamkeitssequenz Parallelism Plus (LASP). Optimiert für die 8-Bit-Quantisierung für eine effiziente Inferenz auf 8x80 GB H100-Knoten.
- Trainingsdaten: trainiert auf rund 12 Billionen Token mit einem WSD-ähnlichen Lernrate-Zeitplan. Die Daten umfassten eine Mischung aus hoch- und minderwertigen Quellen mit globaler Deduplizierung und 4x-Wiederholung für hochwertige Daten.
- Langkontext-Training: Ein dreiphasiertes Ansatz: Phase 1 (128K-Kontext), Phase 2 (512K-Kontext) und Phase 3 (1M-Kontext) unter Verwendung der linearen Interpolation zur Verwaltung der Verteilungsverschiebungen während der Kontextlänge.
- iterative Feinabstimmung: Zyklen der beaufsichtigten Feinabstimmung (SFT) und Verstärkungslernen (RL), die Offline-DPO und Online-Grpo zur Ausrichtung verwendet.
- Langkontext Feinabstimmung: Ein phasenvertretender Ansatz: Kurzkontext SFT → Langkontext SFT → Kurzkontext RL → Long-Context RL, entscheidend für die überlegene Langkontextleistung.
- Deepnorm: Eine Architektur nach der Norm, die die Skalierung und die Trainingsstabilität der verbleibenden Verbindung verbessert.
- Stapelgröße Aufwärmen: erhöht die Stapelgröße nach und nach von 16 m auf 128 m Token für eine optimale Trainingsdynamik.
- Effiziente Parallelität: nutzt die Aufmerksamkeit von Ring, um den Speicheraufwand für lange Sequenzen und die Polsteroptimierung zu minimieren, um die Verschwendung zu reduzieren.
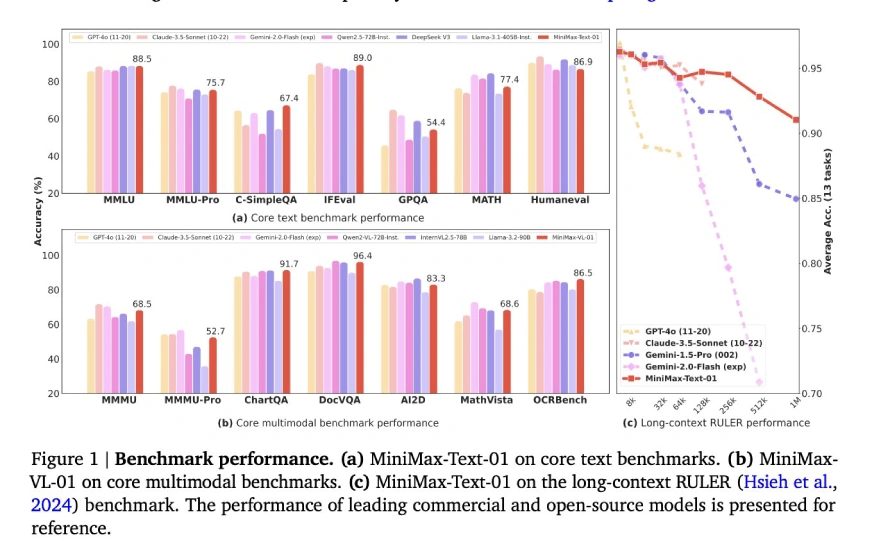
(Tabellen, die Benchmark -Ergebnisse für allgemeine Aufgaben, Argumentationsaufgaben und Mathematik- und Codierungsaufgaben enthalten, sind hier enthalten, die die Tabellen der ursprünglichen Eingabe spiegeln.)

(zusätzliche Bewertungsparameter verbleiben)
Erste Schritte mit Minimax-text-01
(Code-Beispiel für die Verwendung von Minimax-Text-01 mit umarmenden Gesichtstransformatoren bleibt gleich.)
Wichtige Links
- chatbot
- Online -API
- Dokumentation
Schlussfolgerung
minimax-text-01 zeigt beeindruckende Fähigkeiten und erzielte eine modernste Leistung bei langen Kontext- und allgemeinen Aufgaben. Während Verbesserungsbereiche existieren, machen seine Open-Source-Natur, die Kosteneffizienz und die innovative Architektur es zu einem bedeutenden Akteur im KI-Bereich. Es ist besonders für speicherintensive und komplexe Argumentationsanwendungen geeignet, obwohl eine weitere Verfeinerung der Codierungsaufgaben von Vorteil sein kann.
Das obige ist der detaillierte Inhalt von4m Token? Minimax-text-01 übertrifft Deepseek v3. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1670
1670
 14
1428
52
1329
25
1276
29
1256
24
14
1428
52
1329
25
1276
29
1256
24

 Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Während der Arbeit an Agentic AI navigieren Entwickler häufig die Kompromisse zwischen Geschwindigkeit, Flexibilität und Ressourceneffizienz. Ich habe den Agenten-KI-Framework untersucht und bin auf Agno gestoßen (früher war es phi-
 Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
SQL -Änderungstabellanweisung: Dynamisches Hinzufügen von Spalten zu Ihrer Datenbank Im Datenmanagement ist die Anpassungsfähigkeit von SQL von entscheidender Bedeutung. Müssen Sie Ihre Datenbankstruktur im laufenden Flug anpassen? Die Änderungstabelleerklärung ist Ihre Lösung. Diese Anleitung Details Hinzufügen von Colu
 OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
Die Veröffentlichung umfasst drei verschiedene Modelle, GPT-4.1, GPT-4.1 Mini und GPT-4.1-Nano, die einen Zug zu aufgabenspezifischen Optimierungen innerhalb der Landschaft des Großsprachenmodells signalisieren. Diese Modelle ersetzen nicht sofort benutzergerichtete Schnittstellen wie
 Jenseits des Lama -Dramas: 4 neue Benchmarks für große Sprachmodelle
Apr 14, 2025 am 11:09 AM
Jenseits des Lama -Dramas: 4 neue Benchmarks für große Sprachmodelle
Apr 14, 2025 am 11:09 AM
Schwierige Benchmarks: Eine Lama -Fallstudie Anfang April 2025 stellte Meta seine Lama 4-Suite von Models vor und stellte beeindruckende Leistungsmetriken vor, die sie positiv gegen Konkurrenten wie GPT-4O und Claude 3.5 Sonnet positionierten. Zentral im Launc
 Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Schalte die Kraft des Einbettungsmodelle frei: einen tiefen Eintauchen in den neuen Kurs von Andrew Ng Stellen Sie sich eine Zukunft vor, in der Maschinen Ihre Fragen mit perfekter Genauigkeit verstehen und beantworten. Dies ist keine Science -Fiction; Dank der Fortschritte in der KI wird es zu einem R
 Wie ADHS -Spiele, Gesundheitstools und KI -Chatbots die globale Gesundheit verändern
Apr 14, 2025 am 11:27 AM
Wie ADHS -Spiele, Gesundheitstools und KI -Chatbots die globale Gesundheit verändern
Apr 14, 2025 am 11:27 AM
Kann ein Videospiel Angst erleichtern, Fokus aufbauen oder ein Kind mit ADHS unterstützen? Da die Herausforderungen im Gesundheitswesen weltweit steigen - insbesondere bei Jugendlichen - wenden sich Innovatoren einem unwahrscheinlichen Tool zu: Videospiele. Jetzt einer der größten Unterhaltungsindus der Welt
 Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulieren Raketenstarts mit Rocketpy: Eine umfassende Anleitung Dieser Artikel führt Sie durch die Simulation von Rocketpy-Starts mit hoher Leistung mit Rocketpy, einer leistungsstarken Python-Bibliothek. Wir werden alles abdecken, von der Definition von Raketenkomponenten bis zur Analyse von Simula
 Google enthüllt die umfassendste Agentenstrategie bei Cloud nächsten 2025
Apr 15, 2025 am 11:14 AM
Google enthüllt die umfassendste Agentenstrategie bei Cloud nächsten 2025
Apr 15, 2025 am 11:14 AM
Gemini als Grundlage der KI -Strategie von Google Gemini ist der Eckpfeiler der AI -Agentenstrategie von Google und nutzt seine erweiterten multimodalen Funktionen, um Antworten auf Text, Bilder, Audio, Video und Code zu verarbeiten und zu generieren. Entwickelt von Deepm
