
 Technologie-Peripheriegeräte
KI
Erzeugung multimodaler Finanzberichte unter Verwendung von Llamaindex
Technologie-Peripheriegeräte
KI
Erzeugung multimodaler Finanzberichte unter Verwendung von Llamaindex
Erzeugung multimodaler Finanzberichte unter Verwendung von Llamaindex

In vielen realen Anwendungen sind Daten nicht rein textuell-es kann Bilder, Tabellen und Diagramme enthalten, die dazu beitragen, die Erzählung zu verstärken. Mit einem multimodalen Berichtsgenerator können Sie sowohl Text als auch Bilder in eine endgültige Ausgabe einbeziehen, wodurch Ihre Berichte dynamischer und visuell reicher werden.
In diesem Artikel wird beschrieben, wie eine solche Pipeline mit:
erstellt wird- llamaindex zum Orchestrieren von Dokumenten Parsing- und Abfrage -Engines,
- OpenAi Sprachmodelle für die Textanalyse,
- llamaparse , um sowohl Text als auch Bilder aus PDF -Dokumenten zu extrahieren,
- Ein Beobachtbarkeitsaufbau mit Arize Phoenix (über Lamatrace) zum Protokollieren und Debuggen.
Das Endergebnis ist eine Pipeline, die ein ganzes PDF -Diagrammdeck - sowohl Text als auch Visuals - verarbeiten und einen strukturierten Bericht erstellen kann, der sowohl Text als auch Bilder enthält.
Lernziele
- Verstehen Sie, wie Sie Text und Visuals für die Erzeugung der effektiven Finanzberichte mit multimodalen Pipelines integrieren.
- Lernen Sie, Lamaindex und Llamaparse für die Erzeugung der Finanzbericht mit strukturierten Ergebnissen zu verwenden.
- Erforschen Sie Llamaparse, um sowohl Text als auch Bilder aus PDF -Dokumenten effektiv zu extrahieren.
- Beobachtbarkeit unter Verwendung von Arize Phoenix (über Lamatrace) zum Protokollieren und Debuggen komplexer Pipelines.
- Erstellen Sie eine strukturierte Abfrage -Engine, um Berichte zu generieren, die Textzusammenfassungen mit visuellen Elementen verschieben.
Dieser Artikel wurde als Teil des Data Science -Blogathon veröffentlicht.
Inhaltsverzeichnis
- Überblick über den Prozess
- Schritt-für-Schritt-Implementierung
- Schritt 1: Installieren und Importieren von Abhängigkeiten
- Schritt 2: Setzen Sie die Beobachtbarkeit
- Schritt 3: STECE Die Daten. Parse the Document with LlamaParse
- Step 6: Associate Text and Images
- Step 7: Build a Summary Index
- Step 8: Define a Structured Output Schema
- Step 9: Create a Structured Query Engine
- Conclusion
- Überblick über den Prozess
- Erstellen eines multimodalen Berichtsgenerators beinhaltet das Erstellen einer Pipeline, die nahtlos Text- und visuelle Elemente aus komplexen Dokumenten wie PDFs integriert. Der Prozess beginnt mit der Installation der erforderlichen Bibliotheken, wie Lamaindex für Dokumente Parsing und Abfrageorchestrierung sowie Lamaparse, um sowohl Text als auch Bilder zu extrahieren. Die Beobachtbarkeit wird unter Verwendung von Arize Phoenix (über Lamatrace) festgelegt, um die Pipeline zu überwachen und zu debuggen.
Sobald das Setup abgeschlossen ist, verarbeitet die Pipeline ein PDF -Dokument, das seinen Inhalt in strukturierten Text analysiert und visuelle Elemente wie Tabellen und Diagramme rendert. Diese analysierten Elemente werden dann zugeordnet und erstellen einen einheitlichen Datensatz. Ein Zusammenfassungsindex wurde entwickelt, um hochrangige Erkenntnisse zu ermöglichen, und eine strukturierte Abfrage-Engine wird entwickelt, um Berichte zu erstellen, die Textanalysen mit relevanten Visuals kombinieren. Das Ergebnis ist ein dynamischer und interaktiver Berichtsgenerator, der statische Dokumente in reichhaltige, multimodale Ausgänge umwandelt, die auf Benutzeranfragen zugeschnitten sind.
Schritt-für-Schritt-Implementierung
Befolgen Sie diese detaillierte Anleitung, um einen multimodalen Berichtsgenerator zu erstellen, vom Einrichten von Abhängigkeiten bis hin zum Generieren strukturierter Ausgänge mit integrierten Text und Bildern. Jeder Schritt sorgt für eine nahtlose Integration von Llamaindex, Llamaparse und Arize Phoenix für eine effiziente und dynamische Pipeline.
Schritt 1: Installieren und Importieren von Abhängigkeiten
Sie benötigen die folgenden Bibliotheken auf Python 3.9.9:
- llama-Index
- llama-parse (für Textbild-Parsen)
- llama-Index-callbacks-arize-phoenix (zur Beobachtbarkeit/Protokollierung)
- nest_asyncio (Um asynchrische Ereignisschleifen in Notizbüchern zu verarbeiten)
!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
Schritt 2: Beobachtbarkeit aufstellen
Wir integrieren in Lamatrace - Llamacloud API (Arize Phoenix). Erhalten Sie zuerst einen API -Schlüssel von llamatrace.com und richten Sie dann Umgebungsvariablen ein, um Spuren an Phoenix zu senden.
Phoenix -API -Schlüssel kann erhalten werden, indem Sie sich hier für Lamatrace anmelden, dann zum unteren linken Bereich navigieren und auf "Tasten" klicken, wo Sie Ihre API -Taste finden sollten.
Zum Beispiel:
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
)Schritt 3: Laden Sie die Daten - erhalten Sie Ihr Foliendeck
Zur Demonstration verwenden wir Conocophillips '2023 Investor Meeting Slide Deck. Wir laden das PDF herunter:
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")Überprüfen Sie, ob sich das PDF -Diasdeck im Datenordner befindet. Wenn Sie es nicht im Datenordner platzieren, und so wie Sie möchten.
Schritt 4: Modelle
einrichtenSie benötigen ein Einbettungsmodell und ein LLM. In diesem Beispiel:
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
Als nächstes registrieren Sie diese als Standard für llamaindex:
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm
Schritt 5: Analysieren Sie das Dokument mit Llamaparse
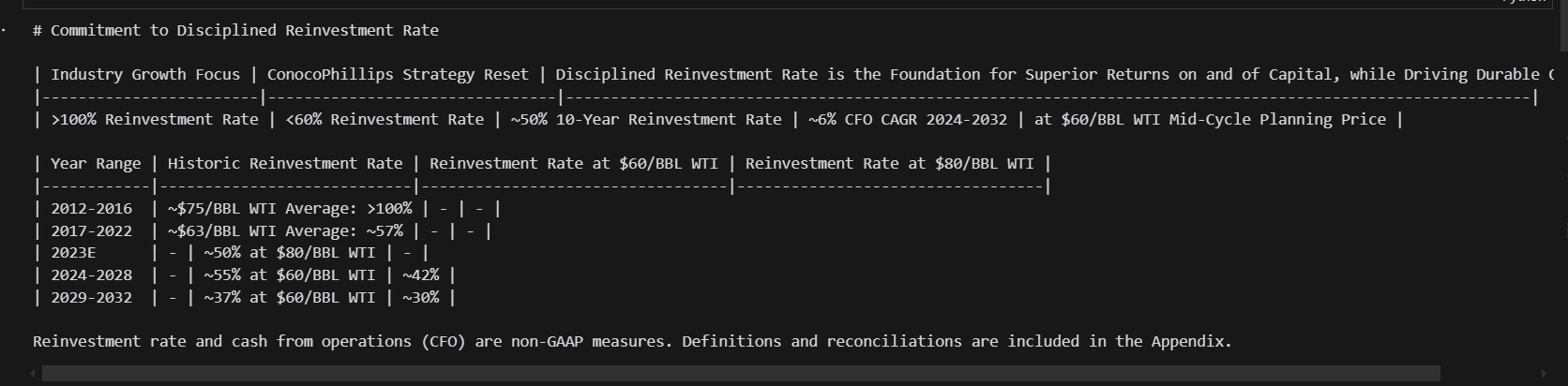
llamaparse kann Text und Bilder extrahieren (über ein multimodales großes Modell). Für jede PDF -Seite kehrt sie zurück:
- Markdown -Text (mit Tabellen, Überschriften, Kugelpunkten usw.)
- ein gerendertes Bild (lokal gespeichert)
print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"] 
print(md_json_list[10]["md"])
print(md_json_list[1].keys())

!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
Schritt 6: Text und Bilder assoziieren
Wir erstellen für jede Seite eine Liste von Textnode Objekte (Lamaindex -Datenstruktur). Jeder Knoten hat Metadaten über die Seitenzahl und den entsprechenden Bilddateipfad:
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
) 
Schritt 7: Erstellen Sie einen zusammenfassenden Index
Mit diesen Textknoten in der Hand können Sie einen zusammenfassendenIndex erstellen:
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")Der SummaryIndex stellt sicher, dass Sie über das gesamte Dokument leicht abrufen oder hochrangige Zusammenfassungen erzeugen können.
Schritt 8: Definieren Sie ein strukturiertes Ausgangsschema
Unsere Pipeline zielt darauf ab, eine endgültige Ausgabe mit verschachtelten Textblöcken und Bildblöcken zu erzeugen. For that, we create a custom Pydantic model (using Pydantic v2 or ensuring compatibility) with two block types—TextBlock and ImageBlock—and a parent model ReportOutput:
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
Der Schlüsselpunkt: reportOutput erfordert mindestens einen Bildblock, um sicherzustellen, dass die endgültige Antwort multimodal ist.
Schritt 9: Erstellen Sie eine strukturierte Abfrage -Engine
Mitllamaindex können Sie ein „strukturiertes LLM“ verwenden (d. H. Ein LLM, dessen Ausgabe automatisch in ein bestimmtes Schema analysiert wird). So ist:
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm

print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"] 
print(md_json_list[10]["md"])

Schlussfolgerung
Durch Kombination von Llamaindex, Llamaparse und OpenAI können Sie einen multimodalen Berichtsgenerator erstellen, der einen gesamten PDF (mit Text, Tabellen und Bildern) in eine strukturierte Ausgabe verarbeitet. Dieser Ansatz liefert umfangreichere und visuell informative Ergebnisse - genau das, was die Stakeholder für kritische Erkenntnisse aus komplexen Unternehmens- oder technischen Dokumenten benötigen.
Sie können diese Pipeline gerne an Ihre eigenen Dokumente anpassen, einen Abrufschritt für große Archive hinzufügen oder domänenspezifische Modelle zur Analyse der zugrunde liegenden Bilder integrieren. Mit den hier festgelegten Grundlagen können Sie dynamische, interaktive und visuell reiche Berichte erstellen, die weit über einfache textbasierte Abfragen hinausgehen.
Ein großes Dankeschön an Jerry Liu von Llamaindex für die Entwicklung dieser erstaunlichen Pipeline.
Key Takeaways
- PDFs mit Text und Visuals in strukturierte Formate verwandeln und gleichzeitig die Integrität des Originalinhalts mithilfe von Llamaparse und LlamaNdex erhalten.
- generieren visuell angereicherte Berichte, die Textzusammenfassungen und Bilder für ein besseres kontextbezogenes Verständnis durcheinander bringen.
- Erzeugung der Finanzberichte kann durch Integration von Text und visuellen Elementen für aufschlussreichere und dynamische Ausgaben verbessert werden.
- Nutzung von Llamaindex und Llamaparse rationalisiert den Prozess der Erzeugung von Finanzberichten und sorgt für genaue und strukturierte Ergebnisse.
- Relevante Dokumente vor der Verarbeitung abrufen, um die Berichterstattung für große Archive zu optimieren.
- Verbesserung der visuellen Analyse, integrieren Sie die chart-spezifische Analysen und kombinieren Sie Modelle für die Text- und Bildverarbeitung für tiefere Erkenntnisse.
häufig gestellte Fragen
Q1. Was ist ein „multimodaler Berichtgenerator“?a. Ein multimodaler Berichtsgenerator ist ein System, das Berichte erstellt, die mehrere Arten von Inhalten - vor allem Text und Bilder - in einer zusammenhängenden Ausgabe enthalten. In dieser Pipeline analysieren Sie ein PDF sowohl in Text- als auch in visuelle Elemente und kombinieren sie dann zu einem einzigen Abschlussbericht.
Q2. Warum muss ich Lama-Index-Callbacks-Arize-Phoenix installieren und die Beobachtbarkeit aufstellen?a. Beobachtbarkeitsinstrumente wie Arize Phoenix (über Lamatrace) können Sie das Modellverhalten des Modells überwachen und debuggen, Abfragen und Antworten verfolgen und Probleme in Echtzeit identifizieren. Es ist besonders nützlich, wenn es um große oder komplexe Dokumente und mehrere LLM-basierte Schritte geht.
Q3. Warum Lamaparse anstelle eines Standard -PDF -Text -Extraktors verwenden?a. Die meisten PDF -Text -Extraktoren verarbeiten nur Rohtext und verlieren häufig Formatierung, Bilder und Tabellen. Llamaparse kann sowohl Text als auch Bilder (gerenderte Seitenbilder) extrahieren, was für die Erstellung multimodaler Pipelines entscheidend ist, wo Sie sich auf Tabellen, Diagramme oder andere Visuals beziehen müssen.
Q4. Was ist der Vorteil der Verwendung eines summaryIndex?a. SummaryIndex ist eine Lamaindex -Abstraktion, die Ihren Inhalt (z. B. Seiten eines PDF) organisiert, damit sie schnell umfassende Zusammenfassungen erzeugen kann. Es hilft, hochrangige Erkenntnisse aus langen Dokumenten zu sammeln, ohne sie manuell einteilen oder eine Abrufabfrage für jedes Datenstück ausführen zu müssen.
Q5. Wie stelle ich sicher, dass der Abschlussbericht mindestens einen Bildblock enthält?a. Durch das pydantische Modell von Reportputs erfordern die Liste der Blöcke mindestens ein ImageBlock. Dies wird in Ihrer System -Eingabeaufforderung und Ihrem System angegeben. Das LLM muss diese Regeln befolgen, oder es erzeugt keine gültige strukturierte Ausgabe.
Die in diesem Artikel gezeigten Medien sind nicht im Besitz von Analytics Vidhya und wird nach Ermessen des Autors verwendet.
Das obige ist der detaillierte Inhalt vonErzeugung multimodaler Finanzberichte unter Verwendung von Llamaindex. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Während der Arbeit an Agentic AI navigieren Entwickler häufig die Kompromisse zwischen Geschwindigkeit, Flexibilität und Ressourceneffizienz. Ich habe den Agenten-KI-Framework untersucht und bin auf Agno gestoßen (früher war es phi-
 Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
SQL -Änderungstabellanweisung: Dynamisches Hinzufügen von Spalten zu Ihrer Datenbank Im Datenmanagement ist die Anpassungsfähigkeit von SQL von entscheidender Bedeutung. Müssen Sie Ihre Datenbankstruktur im laufenden Flug anpassen? Die Änderungstabelleerklärung ist Ihre Lösung. Diese Anleitung Details Hinzufügen von Colu
 OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
Die Veröffentlichung umfasst drei verschiedene Modelle, GPT-4.1, GPT-4.1 Mini und GPT-4.1-Nano, die einen Zug zu aufgabenspezifischen Optimierungen innerhalb der Landschaft des Großsprachenmodells signalisieren. Diese Modelle ersetzen nicht sofort benutzergerichtete Schnittstellen wie
 Jenseits des Lama -Dramas: 4 neue Benchmarks für große Sprachmodelle
Apr 14, 2025 am 11:09 AM
Jenseits des Lama -Dramas: 4 neue Benchmarks für große Sprachmodelle
Apr 14, 2025 am 11:09 AM
Schwierige Benchmarks: Eine Lama -Fallstudie Anfang April 2025 stellte Meta seine Lama 4-Suite von Models vor und stellte beeindruckende Leistungsmetriken vor, die sie positiv gegen Konkurrenten wie GPT-4O und Claude 3.5 Sonnet positionierten. Zentral im Launc
 Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Schalte die Kraft des Einbettungsmodelle frei: einen tiefen Eintauchen in den neuen Kurs von Andrew Ng Stellen Sie sich eine Zukunft vor, in der Maschinen Ihre Fragen mit perfekter Genauigkeit verstehen und beantworten. Dies ist keine Science -Fiction; Dank der Fortschritte in der KI wird es zu einem R
 Wie ADHS -Spiele, Gesundheitstools und KI -Chatbots die globale Gesundheit verändern
Apr 14, 2025 am 11:27 AM
Wie ADHS -Spiele, Gesundheitstools und KI -Chatbots die globale Gesundheit verändern
Apr 14, 2025 am 11:27 AM
Kann ein Videospiel Angst erleichtern, Fokus aufbauen oder ein Kind mit ADHS unterstützen? Da die Herausforderungen im Gesundheitswesen weltweit steigen - insbesondere bei Jugendlichen - wenden sich Innovatoren einem unwahrscheinlichen Tool zu: Videospiele. Jetzt einer der größten Unterhaltungsindus der Welt
 Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulieren Raketenstarts mit Rocketpy: Eine umfassende Anleitung Dieser Artikel führt Sie durch die Simulation von Rocketpy-Starts mit hoher Leistung mit Rocketpy, einer leistungsstarken Python-Bibliothek. Wir werden alles abdecken, von der Definition von Raketenkomponenten bis zur Analyse von Simula
 Google enthüllt die umfassendste Agentenstrategie bei Cloud nächsten 2025
Apr 15, 2025 am 11:14 AM
Google enthüllt die umfassendste Agentenstrategie bei Cloud nächsten 2025
Apr 15, 2025 am 11:14 AM
Gemini als Grundlage der KI -Strategie von Google Gemini ist der Eckpfeiler der AI -Agentenstrategie von Google und nutzt seine erweiterten multimodalen Funktionen, um Antworten auf Text, Bilder, Audio, Video und Code zu verarbeiten und zu generieren. Entwickelt von Deepm
