
 Technologie-Peripheriegeräte
KI
DeepChecks Tutorial: Automatisierung des maschinellen Lerntests
Technologie-Peripheriegeräte
KI
DeepChecks Tutorial: Automatisierung des maschinellen Lerntests
DeepChecks Tutorial: Automatisierung des maschinellen Lerntests

Dieses Tutorial untersucht DeepChecks für Datenvalidierung und maschinelles Lernmodelltest und nutzt Github -Aktionen für automatisierte Tests und Artefakterstellung. Wir werden maschinelles Lernentestsprinzipien, DeepChecks -Funktionalität und einen vollständigen automatisierten Workflow behandeln.

Bild vom Autor
Verständnis für maschinelles Lernen
Effektives maschinelles Lernen erfordert strenge Tests, die über einfache Genauigkeitsmetriken hinausgehen. Wir müssen Fairness, Robustheit und ethische Überlegungen beurteilen, einschließlich der Erkennung von Voreingenommenheit, falsch positiven Aspekten/Negativen, Leistungsmetriken, Durchsatz und Ausrichtung auf die AI -Ethik. Dies beinhaltet Techniken wie Datenvalidierung, Kreuzvalidation, F1-Score-Berechnung, Verwirrungsmatrixanalyse und Drifterkennung (Daten und Vorhersage). Die Datenaufteilung (Zug/Test/Validierung) ist für eine zuverlässige Modellbewertung von entscheidender Bedeutung. Die Automatisierung dieses Vorgangs ist der Schlüssel zum Erstellen von zuverlässigen KI -Systemen.
Für Anfänger bietet die Grundlagen für maschinelles Lernen mit Python Skill Track eine solide Grundlage.
DeepChecks, eine Open-Source-Python-Bibliothek, vereinfacht umfassende Tests für maschinelles Lernen. Es bietet integrierte Überprüfungen für Modellleistung, Datenintegrität und -verteilung und unterstützt die kontinuierliche Validierung für eine zuverlässige Modellbereitstellung.
Erste Schritte mit DeepChecks
DeepChecks mit PIP installieren:
pip install deepchecks --upgrade -q
Datenlast und Vorbereitung (Darlehensdatensatz)
Wir werden den Kreditdatensatz aus DataCamp verwenden.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head() 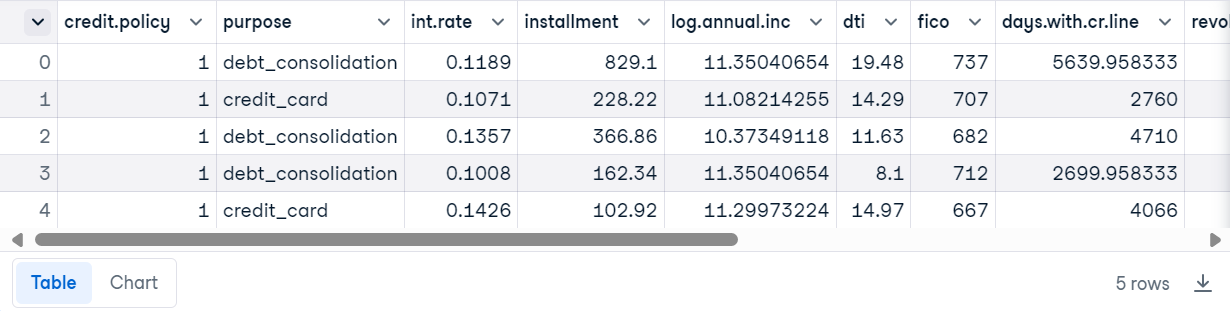
Erstellen Sie einen DeepChecks -Datensatz:
from sklearn.model_selection import train_test_split from deepchecks.tabular import Dataset label_col = 'not.fully.paid' deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])
Datenintegritätstest
DeepChecks 'Datenintegritätssuite führt automatisierte Überprüfungen durch.
from deepchecks.tabular.suites import data_integrity integ_suite = data_integrity() suite_result = integ_suite.run(deep_loan_data) suite_result.show_in_iframe() # Use show_in_iframe for DataLab compatibility
Dies erzeugt eine Berichtsabdeckung: Korrelation für Merkmalsmarke, Korrelation mit Merkmalsfunktionen, Einzelwertüberprüfungen, spezielle Zeichenkennung, Nullwertanalyse, Konsistenz des Datentyps, String-Fehlpaarungen, doppelte Erkennung, Stringlängenvalidierung, widersprüchliche Bezeichnungen und Ausflüssigkeitserkennung.
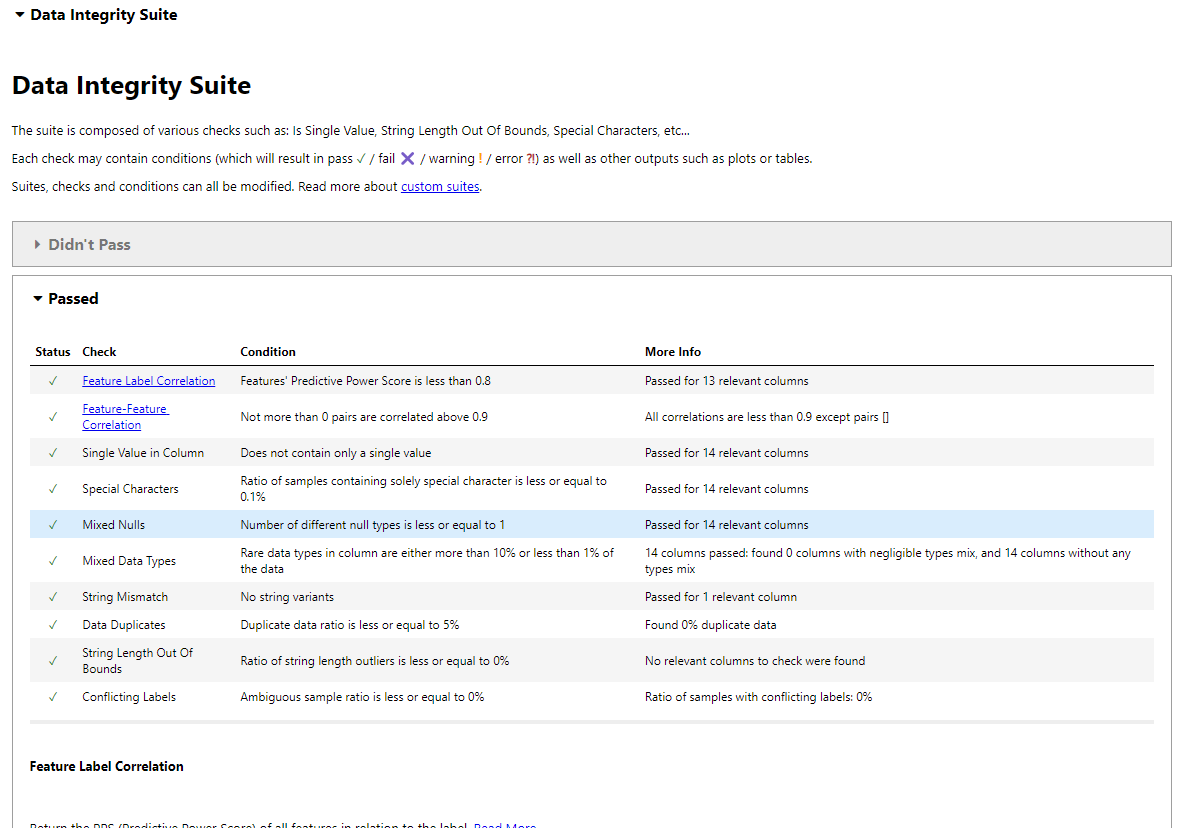
Speichern Sie den Bericht:
suite_result.save_as_html()
individuelle Testausführung
Führen Sie für Effizienz einzelne Tests aus:
from deepchecks.tabular.checks import IsSingleValue, DataDuplicates result = IsSingleValue().run(deep_loan_data) print(result.value) # Unique value counts per column result = DataDuplicates().run(deep_loan_data) print(result.value) # Duplicate sample count
Modellbewertung mit DeepCecks
Wir schulen ein Ensemble -Modell (logistische Regression, zufällige Wald, Gaußsche naive Bayes) und bewerten es mit DeepChecks.
pip install deepchecks --upgrade -q
Der Modellbewertungsbericht umfasst: ROC-Kurven, schwache Segmentleistung, unbenutzte Merkmalserkennung, Zugtestvergleich, Vorhersagedriftanalyse, einfache Modellvergleiche, Modellinferenzzeit, Verwirrungsmatrizen und mehr.

JSON Ausgabe:
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()Individuelle Testbeispiel (Label Drift):
from sklearn.model_selection import train_test_split from deepchecks.tabular import Dataset label_col = 'not.fully.paid' deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])
automatisieren mit Github -Aktionen
In diesem Abschnitt werden ein Workflow für GitHub -Aktionen zur Automatisierung der Datenvalidierung und des Modelltests angezeigt. Der Prozess beinhaltet das Erstellen eines Repositorys, das Hinzufügen von Daten- und Python -Skripten (data_validation.py, train_validation.py) und das Konfigurieren eines Workflows (main.yml) für GitHub -Aktionen, um diese Skripte auszuführen und die Ergebnisse als Artefakte zu speichern. Detaillierte Schritte und Codeausschnitte finden Sie in der ursprünglichen Eingabe. Ein vollständiges Beispiel finden Sie im Repository kingabzpro/Automating-Machine-Learning-Testing Repository. Der Workflow verwendet die Aktionen actions/checkout, actions/setup-python und actions/upload-artifact.
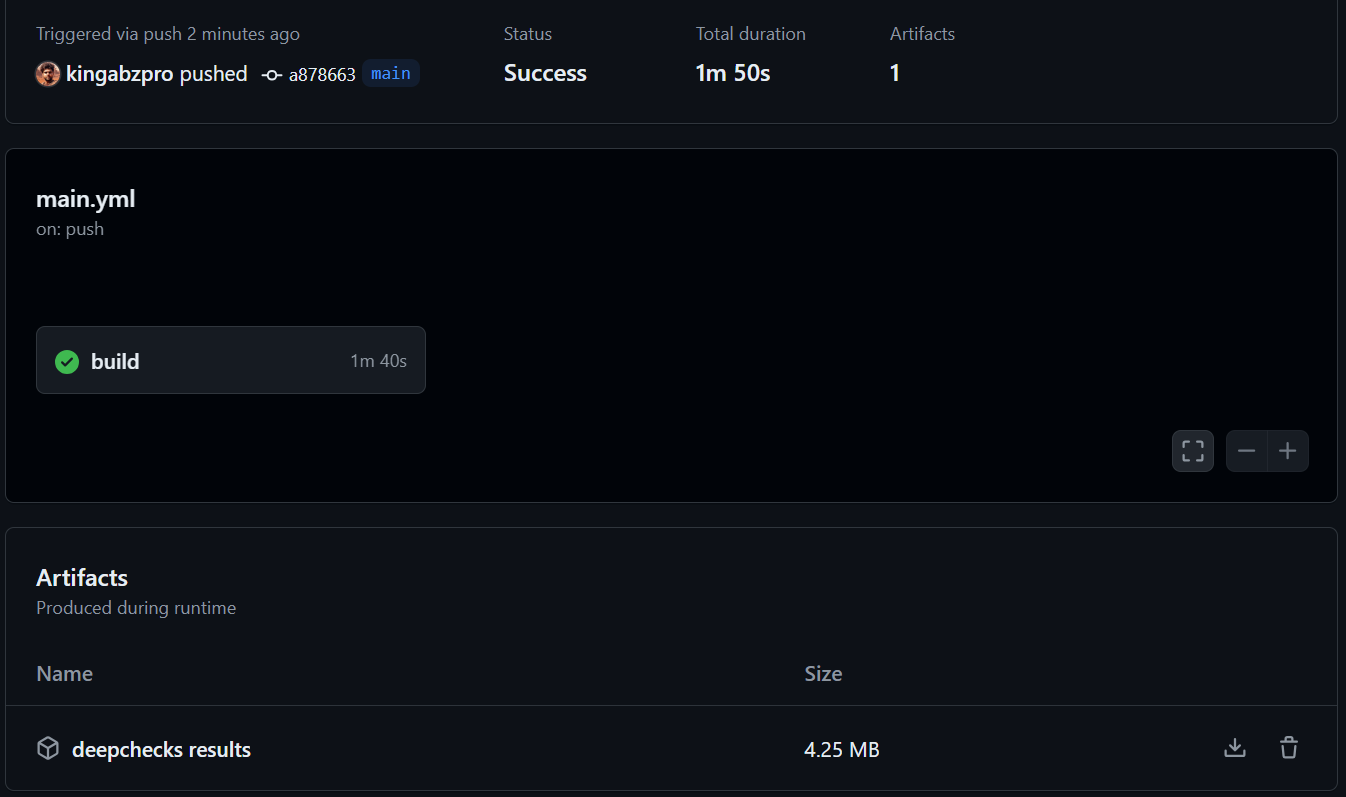
Schlussfolgerung
Das automatische Automatisieren von maschinellem Lernen mit DeepChecks und GitHub -Aktionen verbessert die Effizienz und Zuverlässigkeit erheblich. Die frühzeitige Erkennung von Problemen verbessert die Modellgenauigkeit und Fairness. Dieses Tutorial bietet einen praktischen Leitfaden zur Implementierung dieses Workflows, mit dem Entwickler robustere und vertrauenswürdigere KI -Systeme aufbauen können. Betrachten Sie den Wissenschaftler für maschinelles Lernen mit Python Career Track für die Weiterentwicklung in diesem Bereich.
Das obige ist der detaillierte Inhalt vonDeepChecks Tutorial: Automatisierung des maschinellen Lerntests. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1664
1664
 14
1423
52
1317
25
1268
29
1243
24
14
1423
52
1317
25
1268
29
1243
24

 Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Metas Lama 3.2: Ein Sprung nach vorne in der multimodalen und mobilen KI Meta hat kürzlich Lama 3.2 vorgestellt, ein bedeutender Fortschritt in der KI mit leistungsstarken Sichtfunktionen und leichten Textmodellen, die für mobile Geräte optimiert sind. Aufbau auf dem Erfolg o
 10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
Hey da, codieren Ninja! Welche Codierungsaufgaben haben Sie für den Tag geplant? Bevor Sie weiter in diesen Blog eintauchen, möchte ich, dass Sie über all Ihre Coding-Leiden nachdenken-die Auflistung auflisten diese auf. Erledigt? - Lassen Sie ’
 AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
Die KI -Landschaft dieser Woche: Ein Wirbelsturm von Fortschritten, ethischen Überlegungen und regulatorischen Debatten. Hauptakteure wie OpenAI, Google, Meta und Microsoft haben einen Strom von Updates veröffentlicht, von bahnbrechenden neuen Modellen bis hin zu entscheidenden Verschiebungen in LE
 Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Das jüngste Memo von Shopify -CEO Tobi Lütke erklärt kühn für jeden Mitarbeiter eine grundlegende Erwartung und kennzeichnet eine bedeutende kulturelle Veränderung innerhalb des Unternehmens. Dies ist kein flüchtiger Trend; Es ist ein neues operatives Paradigma, das in P integriert ist
 GPT-4O gegen OpenAI O1: Ist das neue OpenAI-Modell den Hype wert?
Apr 13, 2025 am 10:18 AM
GPT-4O gegen OpenAI O1: Ist das neue OpenAI-Modell den Hype wert?
Apr 13, 2025 am 10:18 AM
Einführung OpenAI hat sein neues Modell auf der Grundlage der mit Spannung erwarteten „Strawberry“ -Scharchitektur veröffentlicht. Dieses innovative Modell, bekannt als O1
 Ein umfassender Leitfaden zu Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
Ein umfassender Leitfaden zu Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
Einführung Stellen Sie sich vor, Sie gehen durch eine Kunstgalerie, umgeben von lebhaften Gemälden und Skulpturen. Was wäre, wenn Sie jedem Stück eine Frage stellen und eine sinnvolle Antwort erhalten könnten? Sie könnten fragen: „Welche Geschichte erzählst du?
 3 Methoden zum Ausführen von LLAMA 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
3 Methoden zum Ausführen von LLAMA 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
METAs Lama 3.2: Ein multimodales KI -Kraftpaket Das neueste multimodale Modell von META, Lama 3.2, stellt einen erheblichen Fortschritt in der KI dar, das ein verbessertes Sprachverständnis, eine verbesserte Genauigkeit und die überlegenen Funktionen der Textgenerierung bietet. Seine Fähigkeit t
 Neueste jährliche Zusammenstellung der besten technischen Techniken
Apr 10, 2025 am 11:22 AM
Neueste jährliche Zusammenstellung der besten technischen Techniken
Apr 10, 2025 am 11:22 AM
Für diejenigen unter Ihnen, die in meiner Kolumne neu sein könnten, erforsche ich allgemein die neuesten Fortschritte in der KI auf dem gesamten Vorstand, einschließlich Themen wie verkörpertes KI, KI-Argumentation, High-Tech
