
这篇文章主要介绍了python模拟登录的多种方法,大概给大家提供了四种方法,每种方法给大家介绍的都很详细,感兴趣的朋友一起看看吧
正文
特点:
简单,但需要先在浏览器登录
原理:
简单地说,cookie保存在发起请求的客户端中,服务器利用cookie来区分不同的客户端。因为http是一种无状态的连接,当服务器一下子收到好几个请求时,是无法判断出哪些请求是同一个客户端发起的。而“访问登录后才能看到的页面”这一行为,恰恰需要客户端向服务器证明:“我是刚才登录过的那个客户端”。于是就需要cookie来标识客户端的身份,以存储它的信息(如登录状态)。
当然,这也意味着,只要得到了别的客户端的cookie,我们就可以假冒成它来和服务器对话。这给我们的程序带来了可乘之机。
我们先用浏览器登录,然后使用开发者工具查看cookie。接着在程序中携带该cookie向网站发送请求,就能让你的程序假扮成刚才登录的那个浏览器,得到只有登录后才能看到的页面。
具体步骤:
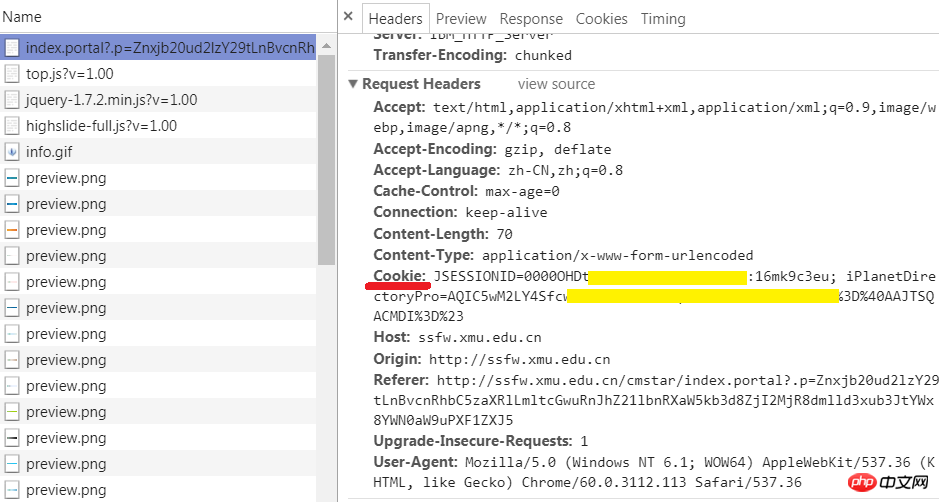
1.用浏览器登录,获取浏览器里的cookie字符串
先使用浏览器登录。再打开开发者工具,转到network选项卡。在左边的Name一栏找到当前的网址,选择右边的Headers选项卡,查看Request Headers,这里包含了该网站颁发给浏览器的cookie。对,就是后面的字符串。把它复制下来,一会儿代码里要用到。
注意,最好是在运行你的程序前再登录。如果太早登录,或是把浏览器关了,很可能复制的那个cookie就过期无效了。
2.写代码
urllib库的版本:
import sys import io from urllib import request sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码 #登录后才能访问的网站 url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal' #浏览器登录后得到的cookie,也就是刚才复制的字符串 cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx' #登录后才能访问的网页 url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal' req = request.Request(url) #设置cookie req.add_header('cookie', raw_cookies) #设置请求头 req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36') resp = request.urlopen(req) print(resp.read().decode('utf-8'))
requests库的版本:
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx'
#把cookie字符串处理成字典,以便接下来使用
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value原理:
我们先在程序中向网站发出登录请求,也就是提交包含登录信息的表单(用户名、密码等)。从响应中得到cookie,今后在访问其他页面时也带上这个cookie,就能得到只有登录后才能看到的页面。
具体步骤:
1.找出表单提交到的页面
还是要利用浏览器的开发者工具。转到network选项卡,并勾选Preserve Log(重要!)。在浏览器里登录网站。然后在左边的Name一栏找到表单提交到的页面。怎么找呢?看看右侧,转到Headers选项卡。首先,在General那段,Request Method应当是POST。其次最下方应该要有一段叫做Form Data的,里面可以看到你刚才输入的用户名和密码等。也可以看看左边的Name,如果含有login这个词,有可能就是提交表单的页面(不一定!)。

这里要强调一点,“表单提交到的页面”通常并不是你填写用户名和密码的页面!所以要利用工具来找到它。
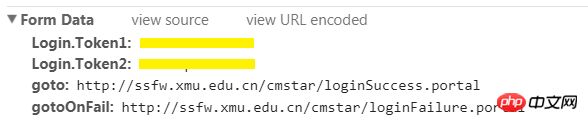
2.找出要提交的数据
虽然你在浏览器里登陆时只填了用户名和密码,但表单里包含的数据可不只这些。从Form Data里就可以看到需要提交的所有数据。
3.写代码
urllib库的版本:
import sys
import io
import urllib.request
import http.cookiejar
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录时需要POST的数据
data = {'Login.Token1':'学号',
'Login.Token2':'密码',
'goto:http':'//ssfw.xmu.edu.cn/cmstar/loginSuccess.portal',
'gotoOnFail:http':'//ssfw.xmu.edu.cn/cmstar/loginFailure.portal'}
post_data = urllib.parse.urlencode(data).encode('utf-8')
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#登录时表单提交到的地址(用开发者工具可以看到)
login_url = ' http://ssfw.xmu.edu.cn/cmstar/userPasswordValidate.portal
#构造登录请求
req = urllib.request.Request(login_url, headers = headers, data = post_data)
#构造cookie
cookie = http.cookiejar.CookieJar()
#由cookie构造opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
#发送登录请求,此后这个opener就携带了cookie,以证明自己登录过
resp = opener.open(req)
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#构造访问请求
req = urllib.request.Request(url, headers = headers)
resp = opener.open(req)
print(resp.read().decode('utf-8'))requests库的版本:
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx'
#把cookie字符串处理成字典,以便接下来使用
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#在发送get请求时带上请求头和cookies
resp = requests.get(url, headers = headers, cookies = cookies)
print(resp.content.decode('utf-8'))明显感觉requests库用着更方便啊~~~
原理:
session是会话的意思。和cookie的相似之处在于,它也可以让服务器“认得”客户端。简单理解就是,把每一个客户端和服务器的互动当作一个“会话”。既然在同一个“会话”里,服务器自然就能知道这个客户端是否登录过。
具体步骤:
1.找出表单提交到的页面
2.找出要提交的数据
这两步和方法二的前两步是一样的
3.写代码
requests库的版本
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录时需要POST的数据
data = {'Login.Token1':'学号',
'Login.Token2':'密码',
'goto:http':'//ssfw.xmu.edu.cn/cmstar/loginSuccess.portal',
'gotoOnFail:http':'//ssfw.xmu.edu.cn/cmstar/loginFailure.portal'}
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#登录时表单提交到的地址(用开发者工具可以看到)
login_url = 'http://ssfw.xmu.edu.cn/cmstar/userPasswordValidate.portal'
#构造Session
session = requests.Session()
#在session中发送登录请求,此后这个session里就存储了cookie
#可以用print(session.cookies.get_dict())查看
resp = session.post(login_url, data)
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#发送访问请求
resp = session.get(url)
print(resp.content.decode('utf-8'))特点:
功能强大,几乎可以对付任何网页,但会导致代码效率低
原理:
如果能在程序里调用一个浏览器来访问网站,那么像登录这样的操作就轻而易举了。在Python中可以使用Selenium库来调用浏览器,写在代码里的操作(打开网页、点击……)会变成浏览器忠实地执行。这个被控制的浏览器可以是Firefox,Chrome等,但最常用的还是PhantomJS这个无头(没有界面)浏览器。也就是说,只要把填写用户名密码、点击“登录”按钮、打开另一个网页等操作写到程序中,PhamtomJS就能确确实实地让你登录上去,并把响应返回给你。
具体步骤:
1.安装selenium库、PhantomJS浏览器
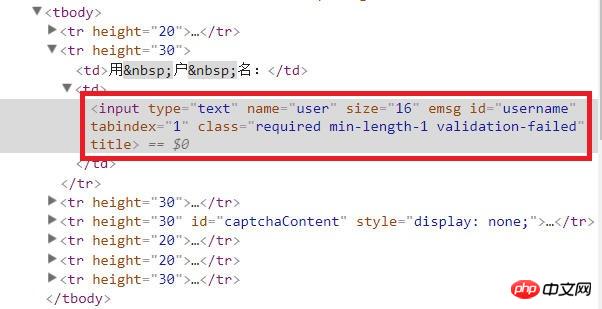
2.在源代码中找到登录时的输入文本框、按钮这些元素
因为要在无头浏览器中进行操作,所以就要先找到输入框,才能输入信息。找到登录按钮,才能点击它。
在浏览器中打开填写用户名密码的页面,将光标移动到输入用户名的文本框,右键,选择“审查元素”,就可以在右边的网页源代码中看到文本框是哪个元素。同理,可以在源代码中找到输入密码的文本框、登录按钮。
3.考虑如何在程序中找到上述元素
Selenium库提供了find_element(s)_by_xxx的方法来找到网页中的输入框、按钮等元素。其中xxx可以是id、name、tag_name(标签名)、class_name(class),也可以是xpath(xpath表达式)等等。当然还是要具体分析网页源代码。
4.写代码
import requests import sys import io from selenium import webdriver sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf8') #改变标准输出的默认编码 #建立Phantomjs浏览器对象,括号里是phantomjs.exe在你的电脑上的路径 browser = webdriver.PhantomJS('d:/tool/07-net/phantomjs-windows/phantomjs-2.1.1-windows/bin/phantomjs.exe') #登录页面 url = r'http://ssfw.xmu.edu.cn/cmstar/index.portal' # 访问登录页面 browser.get(url) # 等待一定时间,让js脚本加载完毕 browser.implicitly_wait(3) #输入用户名 username = browser.find_element_by_name('user') username.send_keys('学号') #输入密码 password = browser.find_element_by_name('pwd') password.send_keys('密码') #选择“学生”单选按钮 student = browser.find_element_by_xpath('//input[@value="student"]') student.click() #点击“登录”按钮 login_button = browser.find_element_by_name('btn') login_button.submit() #网页截图 browser.save_screenshot('picture1.png') #打印网页源代码 print(browser.page_source.encode('utf-8').decode()) browser.quit()
相关推荐:
以上就是Python模拟登录的多种方法的详细内容,更多请关注php中文网其它相关文章!




Copyright 2014-2024 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号



































 0
0 32
32











![ThinkPHP5实战之[教学管理系统]](https://img.php.cn/upload/course/000/000/068/6253d87459486427.png)











