摘要:
List 是 Java Collection Framework的重要成员,具体包括List接口及其所有的实现类。由于List接口继承了Collection接口,所以List拥有Collection的所有操作。同时,又因为List是列表类型,所以List本身还提供了一些适合自身的方法。ArrayList 是一个动态数组,实现了数组动态扩容,随机访问效率高;LinkedList是一个双向链表,随机插入和删除效率高,可用作队列的实现。
一. 要点
List 基础特性与框架
ArrayList :动态数组
LinkedList : 双向循环链表
二. List 基础特性与框架
1、List 特色操作
List 包括 List接口 以及 List接口的所有实现类(ArrayList, LinkedList, Vector,Stack), 其中 Vector 和 Stack 已过时。因为 List 接口实现了 Collection 接口(如代码 1 所示),所以 List 接口拥有 Collection 接口提供的所有常用方法,同时,又因为 List 是列表类型,所以 List 接口还提供了一些适合于自身的常用方法,如表1所示。
// 代码 1public interface List extends Collection { ... }
Copy after login
表1. List 特有的方法(以AbstractList为例说明)
| Function | Introduction | Note |
|---|
| boolean addAll(int index, Collection c) | 将指定 collection 中的所有元素都插入到列表中的指定位置 | 可选操作 |
| E get(int index)| 返回列表中指定位置的元素 | 在 AbstractList 中以抽象方法 abstract public E get(int index); 存在 | AbstractList 中唯一的抽象方法 |
| E set(int index, E element) | 用指定元素替换列表中指定位置的元素 | 可选操作,set 操作是 List 的特有操作 |
| void add(int index, E element) | 在列表的指定位置插入指定元素 | 可选操作 |
| E remove(int index) | 移除列表中指定位置的元素 | 可选操作 |
| int indexOf(Object o) | 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1 | 在 AbstractList 中默认实现;在 ArrayList,LinkedList中分别重写; |
| int lastIndexOf(Object o) | 返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1 | 在 AbstractList 中默认实现;在 ArrayList,LinkedList中分别重写; |
| ListIterator listIterator() | 返回此列表元素的列表迭代器(按适当顺序) | 在 AbstractList 中默认实现,ArrayList,Vector和Stack使用该默认实现,LinkedList重写该实现; |
| ListIterator listIterator(int index) | 返回列表中元素的列表迭代器(按适当顺序),从列表的指定位置开始 | 在 AbstractList 中默认实现,ArrayList,Vector和Stack使用该默认实现,LinkedList重写该实现; |
| List subList(int fromIndex, int toIndex) | 返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的视图 | 在 AbstractList 中默认实现(ArrayList,LinkedList使用该默认实现);之所以说是视图,是因为实际上返回的 list 是靠原来的 list 支持的; |
特别地,对于List而言:
AbstractList 给出了 iterator() 方法的通用实现,其中的 next() 和 remove() 方法底层分别由 get(int index) 和 remove(int index) 方法实现;
对于 subList 方法, 原list 和 子list 做的 非结构性修改(不涉及到list的大小改变的修改),都会影响到彼此; 对于结构性修改: 若发生结构性修改的是返回的子list,那么原list的大小也会发生变化(modCount与expectedModCount同时变化,不会触发Fast-Fail机制) ; 而若发生结构性修改的是原list(不包括由返回的子list导致的改变),那么判断式 l.modCount != expectedModCount 将返回 TRUE ,触发 Fast-Fail 机制,抛出 ConcurrentModificationException。因此,若在调用 sublist 返回了子 list 之后,修改原list的大小,那么之前产生的子list将会失效;
删除一个list的某个区段: list.subList(from, to).clear();
2、List 结构
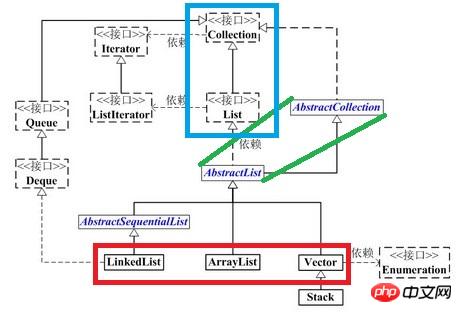
下面我们对 List 结构图中所涉及到的类加以介绍:
AbstractList 是一个抽象类,它实现List接口并继承于 AbstractCollection 。对于“按顺序遍历访问元素”的需求,使用List的Iterator 即可以做到,抽象类AbstractList提供该实现;而访问特定位置的元素(也即按索引访问)、元素的增加和删除涉及到了List中各个元素的连接关系,并没有在AbstractList中提供实现(List 的类型不同,其实现方式也随之不同,所以将具体实现放到子类);
AbstractSequentialList 是一个抽象类,它继承于 AbstractList。AbstractSequentialList 通过 ListIterator 实现了“链表中,根据index索引值操作链表的全部函数”。此外,ArrayList 通过 System.arraycopy(完成元素的挪动) 实现了“顺序表中,根据index索引值操作顺序表的全部函数”;
ArrayList, LinkedList, Vector, Stack 是 List 的 4 个实现类;
ArrayList 是一个动态数组。它由数组实现,随机访问效率高,随机插入、随机删除效率低;
LinkedList 是一个双向链表(顺序表)。LinkedList 随机访问效率低,但随机插入、随机删除效率高,。可以被当作堆栈、队列或双端队列进行操作;
Vector 是矢量队列,和ArrayList一样,它也是一个动态数组,由数组实现。但ArrayList是非线程安全的,而Vector是线程安全的;
Stack 是栈,它继承于Vector。它的特性是:先进后出(FILO, First In Last Out).
3、List 特性:
Java 中的 List 是对数组的有效扩展,它是这样一种结构:如果不使用泛型,它可以容纳任何类型的元素,如果使用泛型,那么它只能容纳泛型指定的类型的元素。和数组(数组不支持泛型)相比,List 的容量是可以动态扩展的;
List 中的元素是“有序”的。这里的“有序”,并不是排序的意思,而是说我们可以对某个元素在集合中的位置进行指定,包括对列表中每个元素的插入位置进行精确地控制、根据元素的整数索引(在列表中的位置)访问元素和搜索列表中的元素;
List 中的元素是可以重复的,因为其为有序的数据结构;
List中常用的集合对象包括:ArrayList、Vector和LinkedList,其中前两者是基于数组来进行存储,后者是基于链表进行存储。其中Vector是线程安全的,其余两个不是线程安全的;
List中是可以包括 null 的,即使使用了泛型;
List 接口提供了特殊的迭代器,称为 ListIterator,除了允许 Iterator 接口提供的正常操作外,该迭代器还允许元素插入和替换,以及双向访问。
三. ArrayList
1、ArrayList 基础
ArrayList 实现了 List 中所有可选操作,并允许包括 NULL 在内的所有元素。除了实现 List 接口外,此类还提供一些方法来操作其支撑数组的大小。ArrayList 是基于数组实现的,是一个动态数组,其容量能自动增长,并且用 size 属性来标识该容器里的元素个数,而非这个被包装数组的大小。每个 ArrayList 实例都有一个容量,该容量是指用来存储列表元素的数组的大小,并且它总是至少等于列表的大小。随着向 ArrayList 中不断添加元素,其容量也自动增长。自动增长会带来数据向新数组的重新拷贝。因此,如果可预知数据量的多少,可在构造ArrayList时指定其容量。在添加大量元素前,应用程序也可以使用 ensureCapacity 操作来增加 ArrayList 实例的容量,这可以减少递增式再分配的数量。注意,此实现不是同步的。如果多个线程同时访问一个 ArrayList 实例,而其中至少一个线程从结构上修改(结构上的修改是指任何添加或删除一个或多个元素的操作,或者显式调整底层数组的大小;仅仅设置元素的值不是结构上的修改.)了列表,那么它必须保持外部同步。
ArrayList 实现了 Serializable 接口,因此它支持序列化,能够通过序列化传输。阅读源码可以发现,ArrayList内置的数组用 transient 关键字修饰,以示其不会被序列化。当然,ArrayList的元素最终还是会被序列化的,在序列化/反序列化时,会调用 ArrayList 的 writeObject()/readObject() 方法,将该 ArrayList中的元素(即0…size-1下标对应的元素) 和 容量大小 写入流/从流读出。这样做的好处是,只保存/传输有实际意义的元素,最大限度的节约了存储、传输和处理的开销。
ArrayList 实现了 RandomAccess 接口, 支持快速随机访问,实际上就是通过下标序号进行快速访问(于是否支持get(index)访问不同)。RandomAccess 接口是 List 实现所使用的标记接口,用来表明其支持快速(通常是固定时间)随机访问。此接口的主要目的是允许一般的算法更改其行为,从而在将其应用到随机或连续访问列表时能提供良好的性能。特别地,在对List的遍历算法中,要尽量来判断是属于 RandomAccess(如ArrayList) 还是 SequenceAccess(如LinkedList),因为适合RandomAccess List的遍历算法,用在SequenceAccess List上就差别很大,即对于实现了RandomAccess接口的类实例而言,此循环
for (int i=0, iCopy after login
的运行速度要快于以下循环:
for (Iterator i=list.iterator(); i.hasNext(); )
i.next();Copy after login
所以,我们在遍历List之前,可以用 if( list instanceof RamdomAccess ) 来判断一下,选择用哪种遍历方式。
ArrayList 实现了Cloneable接口,能被克隆。Cloneable 接口里面没有任何方法,只是起一个标记作用,表明当一个类实现了该接口时,该类可以通过调用clone()方法来克隆该类的实例。
ArrayList不是线程安全的,只能用在单线程环境下,多线程环境下可以考虑用 Collections.synchronizedList(List l) 函数返回一个线程安全的ArrayList类,也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
2、ArrayList在JDK中的定义
我们可以从 ArrayList 的源码看到,其包括 两个域 和 三个构造函数 , 源码如下:
public ArrayList(int initialCapacity){ … } : 给定初始容量的构造函数;
public ArrayList() { … } : Java Collection Framework 规范-默认无参的构造函数 (初始容量指定为10);
public ArrayList(Collectionc) { … } : Java Collection Framework 规范-参数为指定容器的构造函数
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable{
private static final long serialVersionUID = 8683452581122892189L;
/**
* The array buffer into which the elements of the ArrayList are stored.(ArrayList 支撑数组)
* The capacity of the ArrayList is the length of this array buffer.(ArrayList 容量的定义)
*/
private transient Object[] elementData;
// 瞬时域
/**
* The size of the ArrayList (the number of elements it contains).(ArrayList 大小的定义)
*/
private int size; /**
* Constructs an empty list with the specified initial capacity
*/
public ArrayList(int initialCapacity) {
// 给定初始容量的构造函数
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
// 泛型与数组不兼容
} /**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
// Java Collection Framework 规范:默认无参的构造函数
this(10);
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*/
public ArrayList(Collection c) {
// Java Collection Framework 规范:参数为指定容器的构造函数
elementData = c.toArray();
size = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
Copy after login
3、ArrayList 基本操作的保证
// 边界检查private void RangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
}Copy after login
// 调整数组容量
public void ensureCapacity(int minCapacity) {
modCount++;
int oldCapacity = elementData.length;
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3)/2 + 1;
if (newCapacity < minCapacity)
newCapacity = minCapacity;
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}Copy after login
向 ArrayList 中增加元素时,都要去检查添加后元素的个数是否会超出当前数组的长度。如果超出,ArrayList 将会进行扩容,以满足添加数据的需求。数组扩容通过一个 public 方法 ensureCapacity(int minCapacity) 来实现 : 在实际添加大量元素前,我也可以使用 ensureCapacity 来手动增加 ArrayList 实例的容量,以减少递增式再分配的数量。
ArrayList 进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长为其原容量的 1.5 倍 + 1。这种操作的代价是很高的,因此在实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用 ensureCapacity 方法来手动增加ArrayList实例的容量。
在 ensureCapacity 的源代码中有这样一段代码:
Object oldData[] = elementData; //为什么要用到oldData[]
Copy after login
乍一看,后面并没有用到oldData,这句话显得多此一举!但是这牵涉到了一个内存管理的问题. 而且,为什么这一句还在 if 的内部? 这是跟 elementData = Arrays.copyOf(elementData, newCapacity); 这句是有关系的,在下面这句 Arrays.copyOf
的实现时,新创建了 newCapacity 大小的内存,然后把老的 elementData 放入。这样,由于旧的内存的引用是elementData, 而 elementData 指向了新的内存块,如果有一个局部变量 oldData 变量引用旧的内存块的话,在copy的过程中就会比较安全,因为这样证明这块老的内存依然有引用,分配内存的时候就不会被侵占掉。然后,在copy完成后,这个局部变量的生命周期也过去了,此时释放才是安全的。否则的话,在 copy 的时候万一新的内存或其他线程的分配内存侵占了这块老的内存,而 copy 还没有结束,这将是个严重的事情。
调整数组容量(减少容量):将底层数组的容量调整为当前列表保存的实际元素的大小
在使用 ArrayList 过程中,由于 elementData 的长度会被拓展,所以经常会出现 size 很小但 elementData.length 很大的情况,造成空间的浪费。 ArrayList 通过 trimToSize 方法返回一个新的数组给 elementData ,其中:元素内容保持不变,length 和size 相同。
public void trimToSize() {
modCount++;
int oldCapacity = elementData.length;
if (size < oldCapacity) {
elementData = Arrays.copyOf(elementData, size);
}
}Copy after login
private class Itr implements Iterator {
int cursor;
int lastRet = -1;
int expectedModCount = ArrayList.this.modCount;
public boolean hasNext() {
return (this.cursor != ArrayList.this.size);
}
public E next() {
checkForComodification();
/** 省略此处代码 */
}
public void remove() {
if (this.lastRet < 0)
throw new IllegalStateException();
checkForComodification();
/** 省略此处代码 */
}
final void checkForComodification() {
if (ArrayList.this.modCount == this.expectedModCount)
return;
throw new ConcurrentModificationException();
}
}
Copy after login
从上面的源代码我们可以看出,迭代器在调用 next() 、 remove() 方法时都是调用 checkForComodification() 方法,该方法用于判断 “modCount == expectedModCount”:若不等,触发 fail-fast 机制,抛出 ConcurrentModificationException 异常。所以,要弄清楚为什么会产生 fail-fast 机制,我们就必须要弄明白 “modCount != expectedModCount” 什么时候发生,换句话说,他们的值在什么时候发生改变的。
expectedModCount 是在 Itr 中定义的:“int expectedModCount = ArrayList.this.modCount;”,所以它的值是不可能会修改的,所以会变的就是 modCount。modCount 是在 AbstractList 中定义的,为全局变量:
protected transient int modCount = 0;
Copy after login
从 ArrayList 源码中我们可以看出,我们直接或间接的通过 RemoveRange 、 trimToSize 和 ensureCapcity(add,remove,clear) 三个方法完成对 ArrayList 结构上的修改,所以 ArrayList 实例每当调用一次上面的方法,modCount 的值就递增一次。所以,我们这里可以判断:由于expectedModCount 的值与 modCount 的改变不同步,导致两者之间不等,从而触发fail-fast机制。我们可以考虑如下场景:
有两个线程(线程A,线程B),其中线程A负责遍历list、线程B修改list。线程A在遍历list过程的某个时候(此时expectedModCount = modCount=N),线程启动,同时线程B增加一个元素,这是modCount的值发生改变(modCount + 1 = N + 1)。线程A继续遍历执行next方法时,通告checkForComodification方法发现expectedModCount = N ,而modCount = N + 1,两者不等,这时触发 fail-fast机制。
3、元素的增、改、删、查
元素的增和改
ArrayList 提供了 set(int index, E element) 用于修改元素,提供 add(E e)、add(int index, E element)、addAll(Collection c)、addAll(int index, Collection c) 这些方法用于添加元素。
// 用指定的元素替代此列表中指定位置上的元素,并返回以前位于该位置上的元素
public E set(int index, E element) {
RangeCheck(index);
E oldValue = (E) elementData[index];
elementData[index] = element;
return oldValue;
}
// 将指定的元素添加到此列表的尾部public boolean add(E e) {
ensureCapacity(size + 1);
elementData[size++] = e;
return true;
}
// 将指定的元素插入此列表中的指定位置。
// 如果当前位置有元素,则向右移动当前位于该位置的元素以及所有后续元素(将其索引加1)。
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException("Index: "+index+", Size: "+size);
// 如果数组长度不足,将进行扩容。
ensureCapacity(size+1); // Increments modCount!!
// 将 elementData中从Index位置开始、长度为size-index的元素,
// 拷贝到从下标为index+1位置开始的新的elementData数组中。
// 即将当前位于该位置的元素以及所有后续元素右移一个位置。
System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = element;
size++;
}
// 按照指定collection的迭代器所返回的元素顺序,将该collection中的所有元素添加到此列表的尾部。
public boolean addAll(Collection c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacity(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
// 从指定的位置开始,将指定collection中的所有元素插入到此列表中。
public boolean addAll(int index, Collection c) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: " + index + ", Size: " + size);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacity(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew, numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}Copy after login
// 返回此列表中指定位置上的元素。
public E get(int index) {
RangeCheck(index);
return (E) elementData[index];
}Copy after login
romove(int index): 首先是检查范围,修改modCount,保留将要被移除的元素,将移除位置之后的元素向前挪动一个位置,将list末尾元素置空(null),返回被移除的元素。
// 移除此列表中指定位置上的元素
public E remove(int index) {
RangeCheck(index);
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}Copy after login
remove(Object o):
// 移除此列表中 “首次” 出现的指定元素(如果存在)。这是因为 ArrayList 中允许存放重复的元素。
public boolean remove(Object o) {
// 由于ArrayList中允许存放null,因此下面通过两种情况来分别处理。
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
// 类似remove(int index),移除列表中指定位置上的元素。
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
}Copy after login
首先通过代码可以看到,当移除成功后返回true,否则返回false。remove(Object o)中通过遍历element寻找是否存在传入对象,一旦找到就调用 fastRemove 移除对象。
为什么找到了元素就知道了index,不通过remove(index)来移除元素呢?因为fastRemove跳过了判断边界的处理,因为找到元素就相当于确定了index不会超过边界,而且fastRemove并不返回被移除的元素。下面是fastRemove的代码,基本和remove(index)一致。下面是 fastRemove(私有的) 的源码:
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work
}Copy after login
4、小结
关于ArrayList的源码,总结如下:
三个不同的构造方法。无参构造方法构造的ArrayList的容量默认为10; 带有Collection参数的构造方法的实现是将Collection转化为数组赋给ArrayList的实现数组elementData。
扩充容量的方法ensureCapacity。ArrayList在每次增加元素(可能是1个,也可能是一组)时,都要调用该方法来确保足够的容量。当容量不足以容纳当前的元素个数时,就设置新的容量为旧的容量的1.5倍加1,如果设置后的新容量还不够,则直接新容量设置为传入的参数(也就是所需的容量)。之后,用 Arrays.copyof() 方法将元素拷贝到新的数组。从中可以看出,当容量不够时,每次增加元素,都要将原来的元素拷贝到一个新的数组中,非常之耗时,也因此建议在事先能确定元素数量的情况下,才使用ArrayList,否则建议使用LinkedList。
ArrayList 的实现中大量地调用了Arrays.copyof() 和 System.arraycopy()方法 。我们有必要对这两个方法的实现做下深入的了解。首先来看Arrays.copyof()方法。它有很多个重载的方法,但实现思路都是一样的,我们来看泛型版本的源码:
public static T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
Copy after login
很明显调用了另一个 copyof 方法,该方法有三个参数,最后一个参数指明要转换的数据的类型,其源码如下:
/**
* @param original 源数组
* @param newLength 目标数组的长度
* @param newType 目标数组的类型
*/public static T[] copyOf(U[] original, int newLength, Class newType) {
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}Copy after login
这里可以很明显地看出,该方法实际上是在其内部又创建了一个长度为newlength的数组,调用System.arraycopy()方法,将原来数组中的元素复制到了新的数组中。
下面来看 System.arraycopy() 方法。该方法被标记了native,调用了系统的C/C++代码,在JDK中是看不到的,但在openJDK中可以看到其源码。该函数实际上最终调用了C语言的memmove()函数,因此它可以保证同一个数组内元素的正确复制和移动,比一般的复制方法的实现效率要高很多,很适合用来批量处理数组。Java强烈推荐在复制大量数组元素时用该方法,以取得更高的效率;
四. LinkedList
1、LinkedList 简介
LinkedList 是 List接口的双向循环链表实现。LinkedList 实现了 List 中所有可选操作,并且允许所有元素(包括 null)。除了实现 List 接口外,LinkedList 为在列表的开头及结尾进行获取(get)、删除(remove)和插入(insert)元素提供了统一的访问操作,而这些操作允许LinkedList 作为Stack(栈)、Queue(队列)或Deque(双端队列:double-ended queue)进行使用。
注意,LinkedList 不是同步的。如果多个线程同时访问一个顺序表,而其中至少一个线程从结构上(结构修改指添加或删除一个或多个元素的任何操作;仅设置元素的值不是结构修改。)修改了该列表,则它必须保持外部同步。这一般通过对自然封装该列表的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedList 方法来“包装”该列表。最好在创建时完成这一操作,以防止对列表进行意外的不同步访问,如下所示:
List list = Collections.synchronizedList(new LinkedList(...));
Copy after login
LinkedList 的 iterator 和 listIterator 方法返回的迭代器是快速失败的:在迭代器创建之后,如果从结构上对列表进行修改,除非通过迭代器自身的 remove 或 add 方法,其他任何时间任何方式的修改,都将导致ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒将来不确定的时间任意发生不确定行为的风险。
LinkedList 在Java中的定义如下:
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
Copy after login
LinkedList 是一个继承于AbstractSequentialList的双向循环链表。它也可以被当作堆栈、队列或双端队列进行操作;
LinkedList 实现 List 接口,具有 List 的所有功能;
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用;
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆;
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输;
与 ArrayList 不同,LinkedList 没有实现 RandomAccess 接口,不支持快速随机访问。
2、LinkedList 数据结构原理
LinkedList底层的数据结构是基于双向循环链表的,且头结点中不存放数据, 如下:
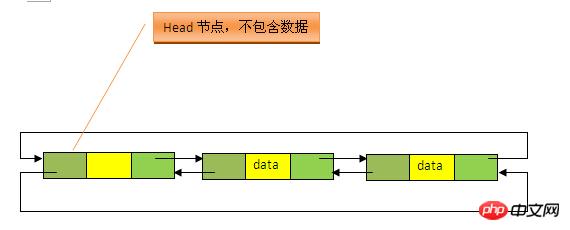
既然是双向链表,那么必定存在一种数据结构——我们可以称之为节点,节点实例保存业务数据,前一个节点的位置信息和后一个节点位置信息,如下图所示:

3、LinkedList 在JDK中的定义
A.成员变量
private transient Entry header = new Entry(null, null, null);
private transient int size = 0;
其中,header是双向链表的头节点,它是Entry的实例。Entry 包含三个成员变量: previous, next, element。其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。 size 是双向链表中节点实例的个数。首先,我们来了解节点类Entry:
private static class Entry {
E element;
Entry next;
Entry previous;
Entry(E element, Entry next, Entry previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
}
Copy after login
节点类 Entry 很简单,element存放业务数据,previous与next分别是指向前后节点的指针。
B.构造函数
- public LinkedList() { … } : Java Collection Framework 规范:空链表
- public LinkedList(Collection c) { … } : Java Collection Framework 规范:参数为指定容器的构造函数
LinkedList提供了两个构造方法。第一个构造方法不接受参数,将header实例的previous和next全部指向header实例(注意,这个是一个双向循环链表,如果不是循环链表,空链表的情况应该是header节点的前一节点和后一节点均为null),这样整个链表其实就只有header一个节点,用于表示一个空的链表。执行完构造函数后,header实例自身形成一个闭环,如下图所示:
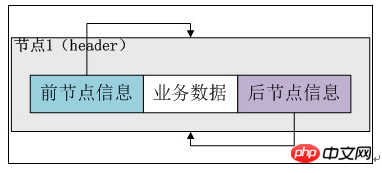
第二个构造方法接收一个Collection参数c,调用第一个构造方法构造一个空的链表,之后通过addAll将c中的元素全部添加到链表中,代码如下:
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable{
private transient Entry header = new Entry(null, null, null);
private transient int size = 0; /**
* Constructs an empty list.
*/
public LinkedList() {
header.next = header.previous = header;
} /**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public LinkedList(Collection c) { this();
addAll(c);
}
Copy after login
C.成员方法
// 将元素(E)添加到LinkedList中
public boolean add(E e) { // 将节点(节点数据是e)添加到表头(header)之前。
// 即,将节点添加到双向链表的末端。
addBefore(e, header); return true;
} public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));
} private Entry addBefore(E e, Entry entry) {
Entry newEntry = new Entry(e, entry, entry.previous);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
modCount++; return newEntry;
}Copy after login
addBefore(E e,Entry entry)方法是个私有方法,其先通过Entry的构造方法创建e的节点newEntry(包含了将其下一个节点设置为entry,上一个节点设置为entry.previous的操作,相当于修改newEntry的“指针”),之后修改插入位置后newEntry的前一节点的next引用和后一节点的previous引用,使链表节点间的引用关系保持正确。之后修改和size大小和记录modCount,然后返回新插入的节点。
private E remove(Entry e) {
if (e == header)
throw new NoSuchElementException(); // 保留将被移除的节点e的内容
E result = e.element; // 将前一节点的next引用赋值为e的下一节点
e.previous.next = e.next; // 将e的下一节点的previous赋值为e的上一节点
e.next.previous = e.previous; // 上面两条语句的执行已经导致了无法在链表中访问到e节点,而下面解除了e节点对前后节点的引用
e.next = e.previous = null; // 将被移除的节点的内容设为null
e.element = null; // 修改size大小
size--;
modCount++; // 返回移除节点e的内容
return result;
}
Copy after login
整个删除操作分为三步:
调整相应节点的前后指针信息
e.previous.next = e.next;//预删除节点的前一节点的后指针指向预删除节点的后一个节点。
e.next.previous = e.previous;//预删除节点的后一节点的前指针指向预删除节点的前一个节点。
清空预删除节点
e.next = e.previous = null;
e.element = null;
gc完成资源回收,删除操作结束。
由以上 add 和 remove 源码可知,与 ArrayList 比较而言,LinkedList的添加、删除动作不需要移动很多数据,从而效率更高。
public E get(int index) {
try {
return listIterator(index).next();
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}Copy after login
该方法涉及到 listIterator 的构造,我们再看listIterator 的源码。
private class ListItr implements ListIterator {
// 最近一次返回的节点,也是当前持有的节点
private Entry lastReturned = header;
// 对下一个元素的引用
private Entry next;
// 下一个节点的index
private int nextIndex;
private int expectedModCount = modCount;
// 构造方法,接收一个index参数,返回一个ListItr对象
ListItr(int index) {
// 如果index小于0或大于size,抛出IndexOutOfBoundsException异常
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size); // 判断遍历方向
if (index < (size >> 1)) { // 相当于除法,但比除法效率高
// next赋值为第一个节点
next = header.next; // 获取指定位置的节点
for (nextIndex=0; nextIndexindex; nextIndex--)
next = next.previous;
}
} // 根据nextIndex是否等于size判断时候还有下一个节点(也可以理解为是否遍历完了LinkedList)
public boolean hasNext() { return nextIndex != size;
} // 获取下一个元素
public E next() {
checkForComodification();
// 如果nextIndex==size,则已经遍历完链表,即没有下一个节点了(实际上是有的,因为是循环链表,任何一个节点都会有上一个和下一个节点,
这里的没有下一个节点只是说所有节点都已经遍历完了)
if (nextIndex == size) throw new NoSuchElementException();
// 设置最近一次返回的节点为next节点
lastReturned = next; // 将next“向后移动一位”
next = next.next; // index计数加1
nextIndex++; // 返回lastReturned的元素
return lastReturned.element;
} public boolean hasPrevious() {
return nextIndex != 0;
}
// 返回上一个节点,和next()方法相似
public E previous() {
if (nextIndex == 0)
throw new NoSuchElementException();
lastReturned = next = next.previous;
nextIndex--;
checkForComodification();
return lastReturned.element;
} public int nextIndex() {
return nextIndex;
} public int previousIndex() {
return nextIndex-1;
} // 移除当前Iterator持有的节点
public void remove() {
checkForComodification();
Entry lastNext = lastReturned.next;
try {
LinkedList.this.remove(lastReturned);
} catch (NoSuchElementException e) {
throw new IllegalStateException();
} if (next==lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = header;
expectedModCount++;
} // 修改当前节点的内容
public void set(E e) {
if (lastReturned == header)
throw new IllegalStateException();
checkForComodification();
lastReturned.element = e;
} // 在当前持有节点后面插入新节点
public void add(E e) {
checkForComodification();
// 将最近一次返回节点修改为header
lastReturned = header;
addBefore(e, next);
nextIndex++;
expectedModCount++;
}
// 判断expectedModCount和modCount是否一致,以确保通过ListItr的修改操作正确的反映在LinkedList中
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
Copy after login
由以上 get 和 listIterator 源码可知,与 ArrayList 比较而言,LinkedList的随机访问需要从头遍历到指定位置元素,而不像ArrayList直接通过索引取值,效率更低一些。
4、小结
关于LinkedList的源码,给出几点比较重要的总结:
LinkedList 本质是一个双向循环链表,可用作List,Queue,Stack和Deque;
LinkedList 并未实现 RandomAccess 接口;
相对于ArrayList,LinkedList有更好的增删效率,更差的随机访问效率;
The above is the detailed content of Java Collection Framework -List具体描述. For more information, please follow other related articles on the PHP Chinese website!
















 0
0 2
2 1266
1266














![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



